Introduction
Hadoop was created in 2006 by engineers working at Yahoo! (most notably, Doug Cutting) with the idea of storing and processing data at internet scale focused on 3 V’s (volume, velocity and variety), defining dimensions of big data. Volume refers to the amount of data, Velocity refers to the speed of data processing, and Variety refers to the number of types of data (structured, unstructured, semi-structured etc). Hadoop delivered on these 3 dimensions utilizing commodity class hardware. This project has been a huge hit, businesses in every vertical have utilized this technology over past few years to power their analytical infrastructures.
The landscape of big data processing has changed, and new cloud based solutions, being more performant, and easier to manage, have become more popular. Additionally, majority of the Hadoop market is controlled by just 1 company (Cloudera), which means support and security updates are limited, and it is increasingly difficult to hire for the specialized skills required to manage and use Hadoop. This means more and more enterprises are in the midst of migrating to newer architectures, or working on a plan to do so.
In this article, we propose a low-risk migration path for on-premise Hadoop customers that allows them to continue to operate from their own data center, thus reducing the cost of cloud. This solution is running in one of our fortune 500 clients in Production for over a year now.
Some Definitions
Lakehouses have become very popular in recent times, especially with Databricks promoting this technology heavily. Let’s look at some definitions:
Data Lake: A data lake is a large, centralized repository for storing all types of data in its raw, unprocessed form. This flexibility allows you
to store all types of data: structured data (csv, tsv, spreadsheets), semi-structured data (json, xml, html), unstructured data (text, images, video).
Data Warehouse: A data warehouse is a database that is optimized for fast, efficient querying and analysis of structured data. These are built to speed up processing of data.
Data Lakehouse: A lakehouse is a new, open architecture that combines the best elements of data lakes and data warehouses. Lakehouses are enabled by a new system design: implementing similar data structures and data management features to those in a data warehouse directly on top of low cost cloud storage in open formats. One important benefit of this architecture is that it serves as the single platform for all types of workloads.
Migration Options
Hadoop in the Cloud
Most obvious solution to modernizing Hadoop is simply to move from an on- premises solution to the cloud, especially if you think the migration can be a simple “lift and shift” – moving all existing data & applications over with zero or minimal changes to code and configuration.
Advantages:
- Potentially no application related changes
- Scalability is simple, since Cloud platforms provide elasticity
- Reduced maintenance
Disadvantages:
- Increased costs
- Vendor lock-in
Migrate to Lakehouse architecture
The most impactful modernization option is to migrate to a data lakehouse.
In the data lake, data is stored in a raw format – so you will often hear it referred to, rather disparagingly, referred to as a data dump. The data warehouse has more organization, but at the cost of constant data engineering, whether with scripts, pipelines, ETL, ELT, or some other process of moving and transforming data. Many practitioners use a rough rule-of-thumb that 80% of the effort in building and managing a data warehouse project is spent on data movement in order to provide a store for BI and reporting tools to work with.
With the lakehouse, various BI and reporting tools have direct access to the data they need without complex and error-prone ETL processes. Additionally, since the data is stored in open file formats like Parquet, data scientists and ML engineers can build models directly on any data (structured, unstructured) depending on their use cases.
Migration Steps
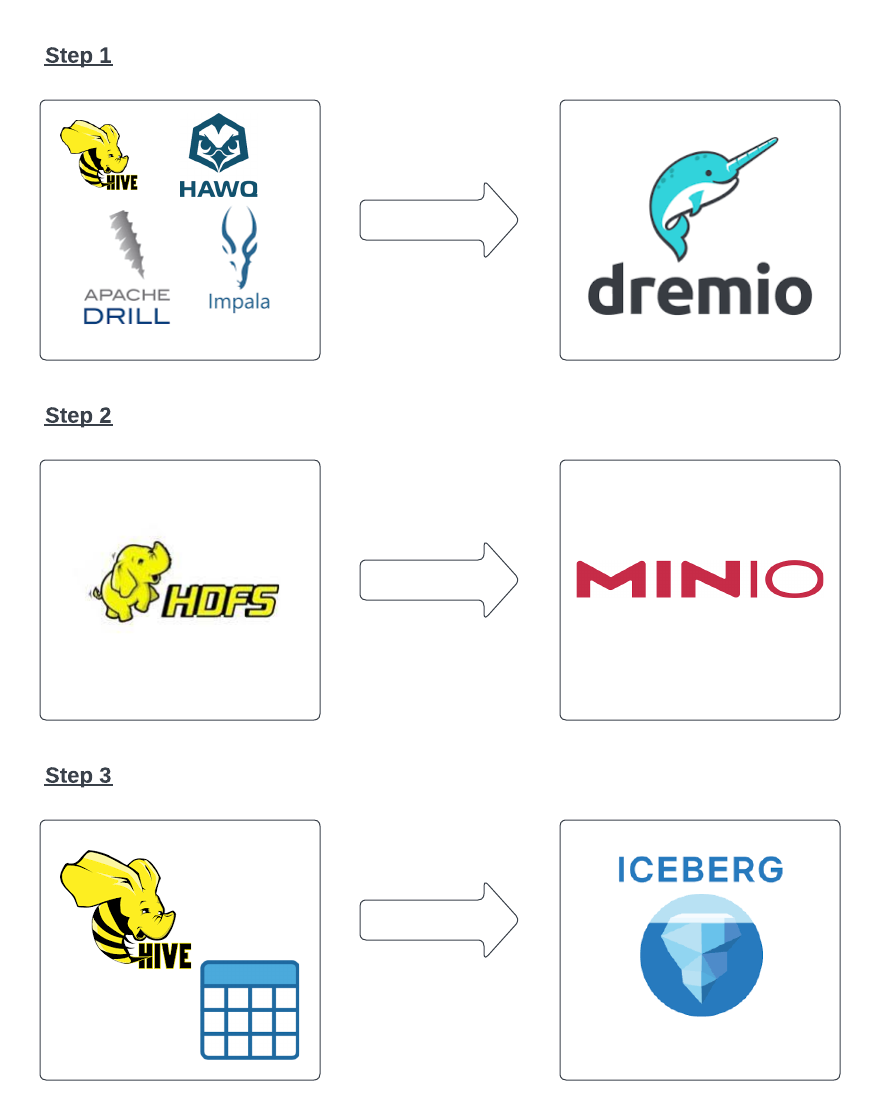
Migrate Compute: Move away from Hadoop based query engines (Hive, Drill, Impala etc) to an open source query engine such as Spark, Presto, Dremio etc. We chose Dremio due to features such as semantic layer, security, and query acceleration using reflections. In addition, Dremio provided built-in support to BI tools that were being used (Tableau and a bit of Power BI) out of the box.
Migrate Storage: Move data from HDFS to S3 compatible object storage (MinIO, Dell ECS, Scality etc). We chose open source version of MinIO for storage.
Create open Data Lakehouse: A key consideration of a data lakehouse design is the table format: a means for tools to look at files in the data lake and see groups of those files as a single table. You can then query and transform the data directly on the data lake, enabling data warehouse-like workloads. There are 3 main table formats available: Apache Iceberg, Apache Hudi and Delta lake.
Customer decided to use Apache Iceberg with features such as ACID transactions, time travel, schema evolution, partition evolution, and more. Iceberg is decoupled from the file layout of Apache Hive, so it can deliver higher performance at scale than other table formats. It’s also open-source which makes it easier for tools and vendors to support this format.
Following table describes old and new tech stack:
| Old Stack | New Stack |
| Hive, Presto | Dremio |
| HDFS | MinIO |
| Hive tables (ORC) | Iceberg tables |
Following picture depicts the steps we discussed earlier in a way to reinforce the message:
Summary
If you are running Hadoop today, and you are most likely considering how to migrate to a new generation of technology. There’s little doubt that Hadoop was revolutionary in its day, but newer generation of technologies provide an easier way to deal with big data problems that enterprises face.
What should that new generation of technology look like? Running Hadoop in the cloud is not really an upgrade. It does improve scalability and maintenance, but it’s still an older technology that affords few new opportunities.
A better option is a data lakehouse. While we have shown one possible combination (Dremio for compute, MinIO for Storage and Iceberg for Lakehouse), one should evaluate other combinations based on needs and technical know-how to implement what’s right for the enterprise.


